If you clicked this blog, AI is not gonna replace you. You want to wander in depth. Want to know when you run git add or git commit ? Let’s peek behind the curtain and explore the secret world inside .git directory.
What is .git, Anyway?
When you execute git init in your project initially, Git creates a hidden .git directory inside the working directory.
Git is like a super-smart filing cabinet that remembers every version of every file you have ever committed. And the .git folder is where that filing cabinet lives.
Now .git is, like Git’s brain, almost all the git’s shenanigans happens here. Git operates as a content-addressable filesystem with a version control interface built on top of it.
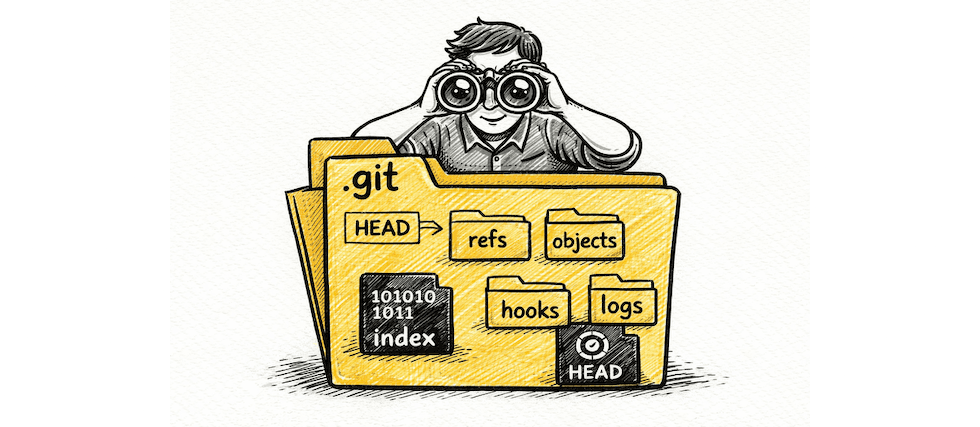
Inside .git
After initializing a new repository, Git creates several key components:
HEAD : A reference to the current branch, like a bookmark.
objects/ : The directory, which is the actual database where Git stores all the files upon commits.
refs/ : Stores pointers to commits e.g. branches, tags etc.
config : Configuration directory containing Git settings specific to your project.
index : The staging area, where tracked files are stored. More of this is discussed later.
hooks/ : Scripts that run automatically on Git events.

Three Musketeers: Blob, Tree and Commit
Git uses three types of objects to track your project.
Blob : A blob stores the content of your files. Not filenames, not directory structures; just pure content. Think of blobs as actual “stuff”.
Tree : Trees organize blobs by storing filenames and directory structures. A tree is like a directory that points to blobs (files) and other trees (sub-directories).
Commit : A commit object references a tree and includes metadata like author, timestamp and parent commits. It is the snapshot of your entire project at a specific point in time.
What Really happens during git add and git commit ?
Let me dissect what happens to these commands you use everyday.
Running git add
Git calculates a SHA-1 hash of your file’s content
The file is compressed and stored as a blob in the objects directory
Index (Staging area) is updated with a reference to this blob
Git stores each object in a sub-directory named with the first two characters of its hash, with the remaining 38 characters as the filename.
Running git commit
Creates a tree object from the staging area
It creates a commit object pointing to that tree
The commit includes your message, author info and timestamp
Current branch pointer moves to this new commit
Essentially, git add stores blobs for changed files and updates the index, while git commit creates tree and commit objects.

The Secret Sauce: SHA-1 Hashes
Git uses SHA-1 hashes as unique identifiers for all objects. Every file, every commit gets a 40-character fingerprint like b69cf9v9f8d9xcv9fdd9v8bf99vfuhrixo76f908.
Why this matters?
Integrity. Even one-bit change changes the hash completely.
Identical files gets the same hash, enforcing deduplication.
git can quickly check if the content exists by looking up its hash.
Summary of it
In Git, everything is content-addressed, where files are stored by their content’s hash.
Each commit is a snapshot, not only diffs.
Branches just point to commits, making them lightweight and fast.
Git is basically a Directed Acyclic Graph (DAG), commits link to their parent commits.
Conclusion
Git is a content-addressable filesystem where blobs store file contents, trees store directory structures, and commits tie everything together with metadata. SHA-1 hashes ensure integrity, and the .git directory is where all this magic lives.