Git Basics through a Practical Model

Search for a command to run...
No comments yet. Be the first to comment.
Every time you type sukanta.dev into your browser to see my cool portfolio, a fascinating chain of events flows behind the scenes. Our computers, as a node in the network, does not know what sukanta.dev, chaicode.com or google.com actually means. It ...
Routers get DNS record and work according to them very well, them fancy telephone directories. But we are not routers, we’re Hoomans (it’s Humans). This article is your go-to if you are new to domains, hosting, starting an agency, or creating your ow...
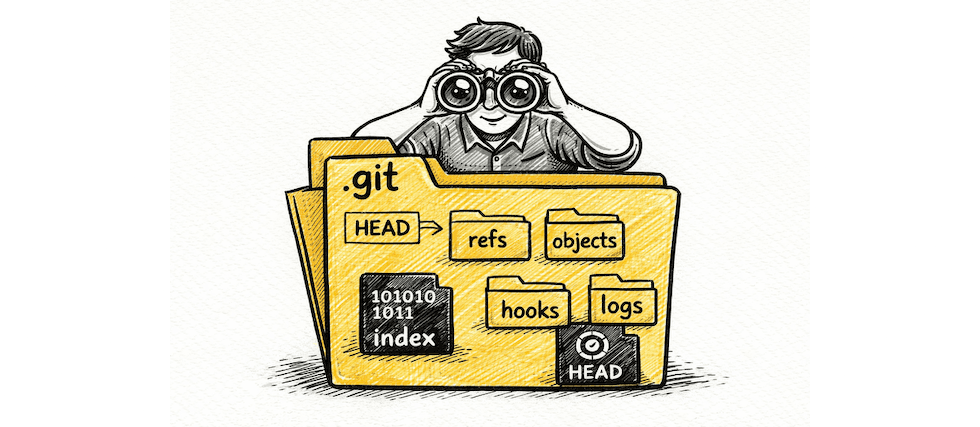
how git works internally, what is inside .git?
From Pendrives to Parallel Development

Sukanta's Blog
5 posts
I learned why git exists the hard way.
I was working on a semester project based on a Python stack. My teammates handled dataset processing and model training, while I worked on the Streamlit UI. Our workflow was on our local machines, the backend team would send me the updated file, and I would build the UI to use it. We worked in it for a week then submitted to our mentor for review.
Everything went smooth before the mentor review.
We got our project feedback, and I realized that was just version 1.0. Now the project needs new features, bug fixes, and potential refactoring.
And my backend storage looked like this:

Get the problem here? The names were ambiguous, files were duplicated, and no one knew which version was actually “correct.” Every change meant another folder, more guessing, and more risk.
So I thought how can we keep track of these files, at a single place, maybe I can use GitHub!
I created a repository, uploaded the files, and thought I was done. When something changed, I planned to upload the modified files again, have a nice day. After some while, a teammate summed it up perfectly:
“bruh just use Google Drive then”. I got humbled and curious. I was just thinking of using GitHub like Google Drive. Then what makes them different? It’s Git.
Git is like a supervisor, looking over your work and taking pictures of changes you made on it, so you can keep track of it, in an organized and efficient way. Formally, Git is a Version Control System (VCS) which helps managing our projects in a versioned manner.
Attention to my phrase “taking pictures” here, that’s what differentiates Git from other VCSs. Git tracks the changes of every file in the directory by taking snapshots of it.
Also, everything git does is totally local by default. Services like GitHub, GitLab, BitBucket etc is just git being run on a server remotely. You can create your own git server by hosting it on any VPS (Virtual Private Server).
thought of articulating some points efficiently, but I already shared my lore, and ChatGPT shared some great points:

Repository: A repository is the working directory you want Git to track, along with the .git folder, which is a database tracking the changes and metadata about the directory. So Repository: Working Directory + .git
Commit: You created a file, made some changes in an existing file, and want to finalize those changes to the next version of the project. That’s when you perform Commit, to finalize, locally.
Branch: Branch is what enabled me and my teammate working on our respective parts and features at the same time, and merge them to the main ones after it got finished.

HEAD: HEAD is a reference to the latest commit in your working directory in the current branch.

Staging Area: The staging area is a checkpoint between your working directory and the repository. It contains only the specific changes you’ve deliberately selected to be included in the next commit.

Birth of a Project (git init): Initializes git for the working directory where the command is executed. This command makes a .git directory, initializes the directory metadata and a database. This should be the first command to start using git for your project.
Selective Addition (git add): Adds the content of added or modified files into the staging area a.k.a. the index. This is the first step towards deciding which makes it to the commit history.
git add <file_path>
git add . # to add all untracked files in the staging area
Making History Permanent (git commit): After the desired changes are made in the working directory, this command adds a new commit containing the current contents of the index (staging area) and the given log message describing the changes.
git commit -m "commit message"
git commit -am "commit message" # add modified files into the staging area and commit

Awareness before action (git status): This command shows the files which have been added/deleted or modified since the latest commit. It shows the path of the tracked files (exists in the staging area), and files that have been untracked as well
Seeing the Past (git log): Logs the commit history in the current branch, along with commit hash, author, date and time, message.

Parallel Timelines (git branch): A branch in Git is a lightweight pointer to a specific version of your project that lets you work on changes in isolation without affecting the main codebase.
In my earlier project setup, creating a new feature meant creating a new folder. With Git, I can create a branch instead.
Instead of this mess
backend/
backend_25jun/
backend_final/
backend_final_fixed/
I can do better:
git branch feat/report
git switch feat/report
Now this is sane and safe, does not tamper the main branch which is currently functional
Understanding Change (git diff): Before Git, you found differences by opening two folders and eyeballing files. That doesn’t scale, and it misses subtle bugs.
git diff shows exact line-by-line difference between the working directory and the staging area or the staging area and the last commit.

It helps finding accidental edits, un-removed debug messages.
git status tells something has changed, git diff shows what changed across commits.
Undoing Mistakes:
git reset: git reset moves the current branch pointer backward to an earlier commit. It is like “pretend this commit never happened”.
Git reset only makes sense if the damage is only local. git reset after pushing it remotely is as useful as starting singing after farting in public. The damage is already done.
git revert: Reverting is undoing without hiding or rewriting the history. git revert adds a new commit, which undoes the changes made in the last commit and performs it as a new commit.
revert is the safest option after the changes have been pushed remotely.
Rewriting History, Responsibly (git rebase): If you are going to stick in this game for long, you are definitely going to make some bunch of small, trivial commits which was necessary for the project, but looks messy while auditing or tracking history.
git rebase just solves that problem by addressing those commits and organizes them into fewer ones, without changing the actual files in the working directory.
Another use-case of git rebase is integrating and reorganizing commit history from another branch.
Leaving the Machine (git push): To collaborate and easy access of your repository, it is convenient to serve your project remotely. git push sends your commits to a remote repository so others can access them.
Now you get the idea of Git and GitHub.
Another point I want to add is: Git is a free and open-source tool created by Linus Torvalds for managing Linux, now it is being managed by the community, for the community. And GitHub is another proprietary piece of Git hosting server with an UI, by Microsoft (what a time to live). Git is a Version Control System, GitHub is a hosting platform.
These commands discussed are enough to get started controlling your project using Git. To learn in-depth, it is always recommended to read the official docs, it IS the gold-standard.
Software development is subjective, it is in it’s nature things will break, and eventually will get fixed. Git gives you the power to attempt your crazy ideas without breaking something which was working few minutes ago.